


México se une a la carrera por la hegemonía en Inteligencia Artificial. MIA el modelo de Lenguaje 100% Mexicano
Modelo para Inteligencias Auto-Regresivas

Las empresas tecnológicas de los países más ricos del mundo han implementado y desplegado los modelos de lenguaje grandes más populares hasta el momento. Entre EU y China se disputa la hegemonía con relación a la tecnología en Inteligencia Artificial con la que contamos hasta el momento, por el lado de EU, corporativos globales tales como Google, Microsoft, Meta, Amazon y OpenAI lideran esta carrera, mientras que las grandes compañías Chinas le siguen de cerca con sus propios desarrollos, así podemos ver que Alibaba y Baidu también han desplegado Modelos de Lenguaje Grandes tan exitosos como lo son las versiones de lado de los EU. En los últimos dos años se estima que empresas de diferentes tamaños en el país Asiático han creado más de 179 modelos de lenguaje, lo que habla de la importancia de esta tecnología para sus Gobiernos y su iniciativa privada. Mientras tanto, ¿Qué es lo que está ocurriendo en México con respecto a esta tecnología?, realmente nada importante y/o trascendente, como en muchas otras industrias estamos siendo vistos como consumidores de dicha tecnología o a lo mucho como manufactureros. A lo largo de mi carrera profesional siempre me he cuestionado ¿Por qué esto es así?, ¿Por qué no tenemos un automóvil de origen Mexicano?, ¿Por qué no tenemos un Smartphone creado en México? y en general ¿Por qué no pasamos de lo 'hecho en México' a lo 'creado en México'?, dicho lo anterior, quizá estoy siendo ingenuo y todo mundo conoce la respuesta a estas preguntas, no obstante, el objetivo de este artículo no es realizar un análisis de las causas raíz de este problema y potenciales soluciones al mismo, si no presentar el primero de una serie de artículos en los que describiré el proceso de mplementación de un modelo de lenguaje de origen cien por ciento mexicano (MIA) basado en la receta replicable descrita en Viaje a la siguiente frontera en IA y que desarrollé con el fin de estudiar las capacidades y limitaciones tanto de la arquitectura Transformer como de sus diferentes encarnaciones y al mismo tiempo analizar la factibilidad de poder emplearlo en productos y/o servicios personalizados a una menor escala dirigidos a las micro, pequeña y medianas empresas, que de acuerdo al INEGI representan el 95% del total de compañias en nuestro país.
El modelo de lenguaje MIA (Modelo para Inteligencias Auto regresivas) como lo he llamado, es un desarrollo propio lo suficientemente robusto y que es una implementación práctica de la receta generada a través de años de investigación por parte de científicos computacionales y de otras disciplinas (la Arquitectura Transformer) al que le agregué un sabor Mexicano, y en este primer artículo describo los pilares fundamentales de dichos Modelos de Lenguaje Grandes y que también aplican para MIA, así que manos a la obra y continuemos en nuestro “Viaje a la siguiente frontera en IA”, ahora acompañados de un pasajero, MIA, el modelo de lenguaje de origen cien por ciento Mexicano.
Los pilares de MIA y los modelos de lenguaje grandes
La arquitectura de los "Modelos de Lenguaje Grandes" descansan sobre dos pilares, Embeddings y el Algoritmo de Atención, el modelo MIA no es la excepción. El modelo MIA al igual que muchos otros modelos de lenguaje grandes, como BERT y GPT, son una implementación de la Arquitectura Transformer, que es uno de los ingredientes indispensables para su creación y que a su vez esta basada sobre los conceptos de Embdeddings y la parelización del algoritmo de atención que describiré en las siguientes secciones, por el momento iniciemos con la analogía que da sustento a toda esta tecnología.
Para aquellos que tenemos la fortuna de tener hijos estarán de acuerdo en lo sorprendente que es escuchar a nuestro bebé pronunciar su primer palabra, que en situaciones normales se da entre los 9 y 12 meses de haber nacido y suele ser la palabra "mamá" (aunque pudiera ser cualquier otra), de alguna forma a esa edad el cerebro de nuestro hijo ha establecido un mapeo (puede verse como una función) entre el sonido de la palabra y su significado con la ayuda de sus diferentes sentidos (oído, vista, tacto, olfato y el gusto) que le permiten experimentar su entorno de tal forma que cuando observa a su progenitora acercarse es capaz reproducir dicho concepto a través de una señal o símbolo sonoro, la palabra "mamá". El concepto asociado a la palabra "mamá" ha sido aprendido por el bebe. Este proceso cognitivo de adquisición del lenguaje continua de forma acelerada durante los siguientes meses y entre los 24 y 36 meses, nuestros hijos son capaces de comprender y generar oraciones lo suficientemente complejas que pueden ser entendidas por los adultos. En condiciones de normalidad, nosotros los seres humanos nacemos equipados con la maquinaria necesaria para adquirir el lenguaje, de alguna forma nuestro cerebro es capaz de codificar las diferentes señales complejas de nuestro entorno, capturando en esta codificación la información de significado clave que nos permite formar un vocabulario y que al combinarlo de forma estructurada genera un significado más amplio al hablar en nuestro idioma nativo. Ahora bien, imaginemos por un momento que se nos encarga la tarea de crear un sistema con la capacidad de comprender y generar nuestra lengua nativa, en otras palabras enseñar a una máquina a hablar, leer y comprender lo leído, ¿Por donde empezaríamos?, ¿Como modelamos este sistema del mundo real que nos hace únicos dentro de las especies?, este reto es precisamente el que se ha abordado por medio de las investigaciones sobre “Procesamiento de Lenguaje Natural" durante mucho tiempo y que ha traído como resultado los "Modelos de Lenguaje Grandes" modernos que actualmente pueden generar texto a partir de un contexto proporcionado dando la "ilusión" de que han adquirido la capacidad de expresarse y comprender lo que se les dice y/o pregunta a través de la IA Conversacional, sin duda alguna, es un logro fascinante el cuál no hubiera sido posible sin dos pilares sobre los que descansan, en adición a las técnicas de aprendizaje profundo que se emplea para entrenarlos, de los cuales no se encuentra exento nuestro modelo MIA. Estos pilares son:
La representación del "significado" de una palabra como un vector. Embeddings.
Un mecanismo para atender a lo más importante dentro de un texto u oración. Mecanismo de Auto-Atención.
Representando el significado de palabras. Embeddings
El reto fue investigar el mejor esquema de codificación que represente de forma compacta (que resulta ser un vector, matemáticamente hablando) el significado de una palabra "emulando" lo que el cerebro de un bebé hace de forma increíblemente eficiente a través de sus cinco sentidos, y que sin embargo, una máquina, al no disponer (hasta el momento) de la riqueza multi-sensorial de un ser humano no podría utilizar como entrada para su procesamiento, por lo que se eligió utilizar el lenguaje escrito como su principal fuente de datos, el cual abunda en nuestra sociedad digital y es lo más cercano a las expresiones de nuestra mente y pensamiento. Así, la tarea es obtener un vector representativo de cada una de las palabras del vocabulario en algún dominio.
Al inicio los esquemas de codificación utilizaron enfoques de vectorización de palabras básicos tomando como base la respuesta a la pregunta, ¿Qué se necesita para extraer el significado de una oración?; que según los expertos en lingüística sería el siguiente conjunto de acciones y componentes:
Dividir la oración en unidades léxicas, lexemas, palabras y frases. Tokenización.
Derivar el significado de cada unidad léxica, esto es, por cada token se genera un vector con una dimensión pre-establecida que codifica su significado. Vectorización.
Comprender la estructura gramatical de la oración. Identificar los patrones gramaticales del lenguaje.
Entender el contexto en el cual aparece una palabra dentro de la oración.
Entonces, de acuerdo a la lingüística la combinación de los datos y acciones anteriores proporcioría la semántica (significado) de las oraciones que leemos en los textos, por lo tanto, de lado computacional sería necesario crear algoritmos que implementaran cada uno de los pasos anteriores de forma eficiente de tal forma que sean útiles en tareas de alto nivel, como la clasificación de una oración como la expresión de un sentimiento positivo, negativo o neutral, tarea que llevo años de investigación y desarrollo.
Los esquemas básicos de codificación creados para tal fin se apoyan en conteos y estadísticas de las palabras utilizadas dentro de un texto, entre estos encontramos:
One-Hot Encoding.
Bag of Words.
Bag of N-Grams.
TF-IDF.
A pesar de su éxito y empleo, todos estos esquemas de codificación de palabras a vectores adolecen de tres problemas fundamentales.
No capturan las relaciones entre las palabras dentro de una oración ya que las tratan como unidades atómicas. Por tanto, no capturan los patrones gramaticales del lenguaje.
Los vectores generados son dispersos y muy grandes (alta dimensionalidad) en función del número existente de palabras en el vocabulario, lo que los hace ineficientes computacionalmente hablando.
No pueden manejar nuevas palabras, es decir, aquellas que no se encuentran en el vocabulario.
Lo que se necesitaba era una representación compacta (vectores de baja dimensionalidad), densa (eficientes en cuanto al uso de memoria) y de tamaño fijo que no esté en función del tamaño del vocabulario como los esquemas de vectorización listados anteriormente. Fue entonces que en su trabajo seminal Mikolov (Efficient Estimation of Word Representations in Vector Space) demostró que su modelo para la representación de palabras como vectores la cual se baso en una red neuronal poco profunda, a la que llamó "Word2vec", podía capturar relaciones de analogía tales como:
Rey es a Hombre como Mujer es a -> Reina.
Su modelo cumple con los requisitos necesarios de una buena representación para el significado de una palabra como un vector, además de haber aprendido ricas relaciones semánticas entre las palabras durante su entrenamiento, los vectores obtenidos con el modelo Word2Vec son de pocas dimensiones (50 a 500), además de ser densos (todas las posiciones del vector están llenas con algún valor y no dispersas como en el caso de algoritmos tradicionales), los vectores resultantes del entrenamiento de esta red neuronal se conocen como Embeddings y son sin duda alguna la primer piedra angular del progreso actual con lo que respecta al procesamiento del lenguaje natural moderno en Inteligencia Artificial, al igual que lo son para nuestro modelo MIA.
La intuición detrás del modelo “Word2Vec”, es simple, y la hemos escuchado muchas veces, al escuchar decir a alguien "El significado de una palabra depende del contexto donde se utilice" dicho de otra forma "El significado de una palabra está en función de las palabras que se encuentran a su alrededor(su contexto)" de tal forma que si dos palabras diferentes ocurren frecuentemente en un contexto similar entonces existe una alta probabilidad de que sus significados sean similares (o que agrupen algún concepto más general), la tarea entonces es encontrar una función que dadas sus palabras contexto predigan la palabra central alrededor de dicho contexto, esto hace que palabras con significados similares tiendan a agruparse y palabras con significados diferentes tiendan a estar lejos unas de otras desde el punto de vista del espacio vectorial al que pertenecen sus vectores representativos.
El modelo Word2Vec define dos variantes arquitectónicas para su implementación:
Bolsa de palabras continuas (CBOW)
Skypgram
Ambos modelos arquitectónicos comparten muchas similitudes y su única diferencia es la palabra a predecir, en el caso de CBOW, la tarea es predecir la palabra central dentro de un contexto mientras que con la opción Skypgram se predice el contexto dada la palabra central. Por ejemplo, dada la siguiente oración:
"Los embeddings son la piedra angular en modelos de lenguaje"
El algoritmo CBOW predecirá la palabra "angular" teniendo como entrada su contexto ((la, piedra, en, modelos), angular), esto es, un dato de entrenamiento para la red neuronal estaría compuesto por (<contexto: lista de palabras antes y después de la palabra a predecir>, <palabra a predecir>) donde la variable independiente X serían los vectores que corresponderían al contexto(vectores de n dimensiones e inicializados aleatoriamente al inicio) y la variable dependiente Y sería la verdadera palabra a predecir (igualmente un vector), y durante el entrenamiento se optimizarían los valores en los vectores inicializados aleatoriamente para así obtener la función de mapeo que nos proporcione la probabilidad de que sea Y' la palabra correcta en ese contexto.
El algoritmo Skypgram hace exactamente lo mismo pero en este caso la variable independiente X es la palabra central, en este caso, "angular" y se predice su contexto ("la","piedra", "en", "modelos"), es decir, las palabras antes y después de la palabra central son la variable dependiente Y en este algoritmo. Bueno, resulta ser que el modelo MIA utiliza una capa Embedding en su arquitectura (recordemos que MIA es un modelo donde aplicamos la misma receta para la creación de Modelos de Lenguaje Grandes, la Arquitectura Transformer) que sirve como entrada de la capa siguiente, que representa el segundo pilar sobre el que descansan los modelos de lenguaje actualmente. En su momento tuve diferentes alternativas para su implementación las cuales explicaré en un artículo posterior junto con la implementación que finalmente utilicé para el modelo MIA, aquí nos limitaremos con decir que el modelo Word2Vec es por mucho el pilar más fuerte sobre el que descansan los modelos de lenguaje grandes actuales y es la primera capa de todos los modelos basados en la “Arquitectura Transformer” así como arquitecturas anteriores a esta como son Redes Neuronales Recurrentes (RNN) y Memoria de Corto Plazo Amplia (LSTM).
El segundo pilar es la implementación computacional de un mecanismo para poner atención a lo más importante dentro de una secuencia de entrada y en la siguiente sección explicó cómo funciona internamente este mecanismo.
Poniendo atención a lo más importante. Mecanismo de Auto-Atención
El lenguaje tanto escrito como hablado resulta de la combinación de palabras que por sí mismas conllevan un significado además de seguir las reglas de una estructura inherente a este, su gramática, y uno de los principales objetivos de nuestra educación básica es precisamente adquirir la habilidad de leer y comprender esta combinación de palabras presente en las narrativas textuales, durante esta fase educativa los profesores se esfuerzan en indicarle a los niños que para contar con un buen entendimiento de lo que estemos leyendo es necesario prestar atención a lo más importante, de forma empírica sabemos que esto tiene que ser así, sin embargo, dentro de una frase, oración, párrafo o texto ¿Cómo le hace nuestro cerebro para poder determinar qué es lo más importante dentro de la combinación de palabras que siguen la gramática del lenguaje en particular en el que está escrito dicho texto?, de alguna forma, nuestro cerebro parece hacerlo todo el tiempo (y no solo cuando leemos) aún cuando no somos consientes de ello, dicho mecanismo se conoce como Atención Cognitiva y el procesamiento de lenguaje natural (podemos reemplazar lenguaje natural con la palabra texto) implementado como redes neuronales tomó como fuente de inspiración dicha capacidad del cerebro humano y la agregaron como otro pilar fundamental del diseño en diferentes arquitecturas entre las que encontramos la más exitosa hasta el momento, la Arquitectura Transformer.
Recapitulando, lo que hoy conocemos como “Modelos de Lenguaje Grandes” están fundamentados sobre las siguientes ideas básicas implementadas como algoritmos computacionales:
La representación del significado de una palabra matemáticamente como un vector. Su Embedding.
El análisis del lenguaje como una combinación de palabras gobernadas por la gramática inherente de este. La palabra clave aquí es, combinación.
El hecho de que para comprender el significado de una oración o texto es necesario prestar atención a lo más importante. Un valor cuantitativo acerca de las relaciones entre combinaciones de pares de palabras.
En la sección anterior describimos cómo el significado de una palabra puede ser representado a través de un vector n-dimensional dentro de un espacio vectorial que agrupa aquellas palabras con significados similares o que se utilizan dentro de un mismo contexto, a estos vectores se les llama Embeddings y como dijimos se calculan por medio de redes neuronales poco profundas, este algoritmo es la formulación matemática de la idea fundamental expresada en el punto número uno de la lista anterior.
El segundo pilar es la formulación de un mecanismo (un algoritmo) que permite modelar las ideas de los puntos dos y tres de nuestra lista de ideas fundamentales y que explico en esta sección. Luego entonces, las preguntas clave son, ¿Como modelamos las diferentes combinaciones de pares de palabras dentro de una oración? y ¿Como calculamos las relaciones más importantes a las que debemos prestar más atención y les asignamos un valor cuantitativo?, para responder a estas cuestiones los diseñadores de la Arquitectura Transformer crearon un procedimiento de cuatro pasos al que llamaron "Mecanismo de auto-atención", el cual ejecutaremos (para fines demostrativos de su operación) utilizando como entrada el siguiente texto:
"Los embeddings son la piedra angular en modelos de lenguaje"
La idea de ejecutar el algoritmo paso a paso es comprender como funciona para después indagar la intuición detrás del mismo, es decir, como llegaron los creadores de la arquitectura a este procedimiento tan exitoso al día de hoy.
Como requisito previo, es necesario realizar un pre-procesamiento del texto de tal forma que el algoritmo pueda tratar con datos numéricos en lugar de cadenas de caracteres, esto se consigue de la siguiente manera:
Estableciendo los datos de entrada al “mecanismo de atención”
Cada una de las palabras que conforman la oración anterior serán la entrada al modelo y como pre-requisito es necesario obtenerlas representadas como tokens, proceso que se conoce como Tokenización, y es realizado usando uno de los múltiples algoritmos para tal efecto, implementados como Tokenizadores, luego, por cada token (por simplicidad, palabra) se obtiene la representación de su significado expresada como su “Embedding”, es decir, un vector de k dimensiones el cual tenemos la libertad de establecer como un parámetro del modelo al configurarlo, por tanto, de acuerdo a la oración que estamos utilizando como ejemplo la salida de este pre-procesamiento seria:
Tokens de la oración (esta es una simplificación, en realidad los algoritmos suelen ser un poco más elaborados, pero por simplicidad representamos un token como una palabra)
["los", "embeddings", "son", "la", "piedra", "angular", "en", "modelos", "de", “lenguaje"]
Los Embeddings de cada palabra, se calculan o ya se encuentran pre-calculados utilizando el modelo presentado por Mikolov (Efficient Estimation of Word Representations in Vector Space)
"los" [ 0.8989 0.3246 0.2678 ... 0.9089 0.1234 ] x1
"embeddings" [ 0.7650 0.2875 0.2980 ... 0.9234 0.4389 ] x2
"son" [ 0.1980 0.1973 0.2012 ... 0.2000 0.2006 ] x3
"piedra" [ 0.6578 0.9849 0.0983 ... 0.7845 0.3209 ] x4
"angular" [ 0.0056 0.2349 0.1067 ... 0.2789 0.2784 ] x5
"en" [ 0.2849 0.1005 0.2389 ... 0.2001 0.1977 ] x6
"modelos" [ 0.6107 0.2609 0.4862 ... 0.6105 0.2020 ] x7
"de" [ 0.0012 0.1189 0.3365 ... 0.4412 0.9812 ] x8
"lenguaje" [ 0.3781 0.2901 0.2042 ... 0.2064 0.2023 ] x9
Esta sería la Matriz de Entrada o Matriz de Embeddings cuyas dimensiones serían m x k donde m = "El número de tokens que conforma la oración", en ese caso 9 y k = "La dimensión del vector embedding deseado como salida", esto puede ser especificado como un hiper-parámetro del modelo, por ejemplo, 512.
Una vez obtenida la Matriz de Embeddings se procede a ejecutar el algoritmo de Auto-Atención cuyo objetivo es calcular a que combinación de palabras se debe prestar más atención (en realidad el valor numérico de atención calculado representa que tan similares son las palabras que conforman determinada combinación. Por ejemplo, que tanta similitud (nivel de atención) existe entre la palabra "los" con respecto a todas las demás palabras, por ejemplo, <combinación Palabra 1 con Palabra 2>"los-embedding"=<nivel de atención>, <combinación Palabra 1 con Palabra 3>"los-son"=<nivel de atención>, <combinación Palabra 1 con Palabra 4>"los-piedra"=<nivel de atención> y así sucesivamente hasta obtener una Matriz de Atención la cual será útil para las siguiente capas de la red neuronal.
Ejecutando los cuatro pasos del Algoritmos de Auto-Atención
El algoritmo de auto-atención (aquel que calcula a que combinación de tokens o palabras se debe prestar más atención dentro de una oración) introduce tres matrices, a saber, Q(matriz de consulta), K(matriz de llaves) y V(matriz de valores) las cuales son creadas a partir de la matriz de entrada o matriz de embeddings X (obtenida del paso de pre-procesamiento) multiplicando esta con las correspondientes matrices de pesos Q’, K’ y V’ las cuales son inicializadas aleatoriamente y cuyos valores óptimos serán calculados durante el entrenamiento, así tenemos que Q = X * Q’, K = X * K’ y V = X * V’, una vez obtenidas las matrices Q, K y V se procede con los cálculos necesarios.
PRIMER PASO - Calcular el producto punto entre la matriz Q y la transpuesta de la matriz K
Este paso puede verse como un análisis cuantitativo de a que combinación de parejas de palabras se debe prestar mas atención en función de su significado expresado como sus embeddings, esto debido a que el producto punto entre dos vectores nos indica que tan similares son estos (que tan relacionados están sus significados). Esta operación puede verse como:

Como se puede observar cada elemento de la matriz que resulta de esta operación representa el peso o atención de la combinación de cada palabra con las otras.
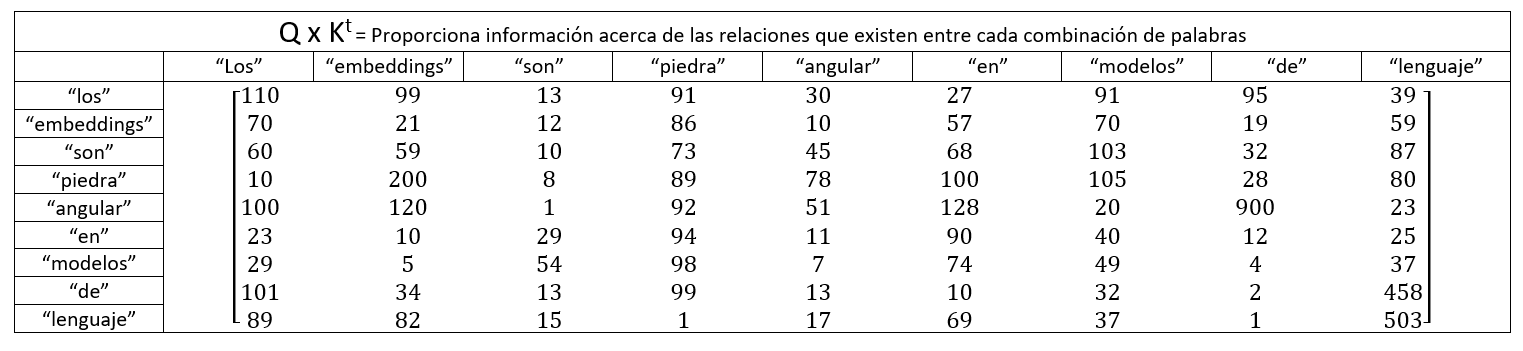
SEGUNDO PASO - Dividir la matriz obtenida en el paso anterior entre la raíz cuadrada de la dimensión elegida para los embeddings de la entrada (dk), esto con el objetivo de obtener gradientes estables ya que la operación anterior generaría valores muy grandes dependiendo de la dimensión del embedding los cuales al ser utilizados para calcular el gradiente se irá desvaneciendo gradualmente lo que repercutiría en problemas de optimización en las funciones objetivo de las redes neuronales.


TERCER PASO - La matriz calculada una vez aplicado el segundo paso contendrá valores grandes por lo que es necesario normalizarlos para que cumplan con el requisito de representar puntajes de atención como porcentajes decimales entre 0 y 1 y que además sumen 1, esto se logra aplicando la función Softmax a cada entrada de la matriz.

CUARTO PASO - Calcular la matriz de atención Z la cuál contendrá valores de atención por cada palabra en la oración, esto se logra multiplicando la matriz del paso anterior con la matriz de valores V.

Los pasos anteriores son el resultado de la evaluación de la ecuación en el encabezado de la imagen anterior descrita en Atención es todo lo que necesitas, como puede verse la ecuación es simple de calcular, pero deja muchas interrogantes que el documento no responde o probablemente asume que ya se conocen de antemano, algunas de dichas preguntas son ¿De dónde provienen la matrices Q, K, V?, ¿Por qué multiplicarlas con la matriz de entrada X que representan los embeddings de cada una de las palabras en la oración?, ¿Cómo es que los autores llegaron a la conclusión de que dichas matrices son necesarias para implementar el concepto de atención cognitiva de forma computacional?, resulta ser que la intuición y/o inspiración detrás de estas matrices se tomó prestada de sistemas de recuperación de información, en los cuales se emplean vectores para realizar búsquedas de entradas de parejas llave-valor en mapas de datos tomando como criterio el significado de las palabras en lugar de una búsqueda exacta (hablaremos de este tema en un artículo posterior donde explicaré de forma detallada los conceptos detrás de dichas matrices y su función en el mecanismo de auto-atención, así como su implementación en el Modelo de Lenguaje MIA).
Una característica importante del algoritmo de atención es que puede ejecutarse de forma paralela haciendo más eficiente el entrenamiento, lo que representó un verdadero parte aguas ya que abrió la posibilidad de crear modelos tan grandes como se quiera en función del presupuesto con el que se cuente, es así, que ahora se habla de modelos de lenguaje grandes que calculan millones o incluso billones de parámetros lo que en teoría implica que emerjan capacidades sobre salientes en dichos modelos.
Modelo de Lenguaje MIA y la Arquitectura Transformer
Como escribí al inicio de este artículo el Modelo de Lenguaje MIA es una implementación de la Arquitectura Transformer y por consiguiente también esta fundamentada sobre los dos pilares que describí arriba, Embeddings y el Mecanismo de Auto-Atención, en los siguientes artículos de esta serie explicaré los diferentes componentes que conforman su Arquitectura, y su funcionamiento interno, de esta forma, expondre que partes tomé de la Arquitectura Transformer para la implementación del modelo MIA y el porqué de dichas elecciones, haciendo énfasis en el hecho de que los Modelos del Lenguaje Grandes actuales que sorprenden a tanta gente en realidad estan basados en una receta replicable y que la única barrera de entrada es el presupuesto con el que se cuente, de allá la urgencia de los gigantes tecnologicos por hacer aún más grande dicha barrera y así proteger sus propios intereses a través de la regulación global, por lo que México como un país autónomo debería contar con su propia versión de algún Modelo de Lenguaje Grande y ¿por qué no? versiones propietarias en empresas privadas, en otras palabras dar el salto de “lo hecho en México” a lo “Creado en México”. El modelo de lenguaje MIA es un ejemplo de que eso es posible.