


Embeddings en el Modelo de Lenguaje MIA
Implementando Word2Vec como capa de entrada en MIA

Una de las primeras capas presentes en la Arquitectura Transformer (sobre la que se basa MIA) es la capa Embedding y como escribí en el artículo “México se une a la carrera por la hegemonía en Inteligencia Artificial” el cálculo de los Embeddings de un vocabulario es uno de los pilares fundamentales de cualquier modelo de lenguaje grande moderno actualmente desplegado, la razón es simple, un embedding codifica el “significado” de una palabra como un vector númerico y Word2Vec es un enfoque para la creación de dichos embeddings que fue un parteaguas en el mundo del Procesamiento de Lenguaje Natural cuando fue presentado en el ya famoso paper Efficient Estimation of Word Representations in Vector Space, debido a esto me resultó interesante realizar un experimento implementando la capa embedding de la arquitectura transformer aprovechando una de las dos arquitecturas descritas en dicho documento de tal forma que el entrenamiento de MIA inicia con un sólido conjunto de embeddgins pre-calculados y específicos al lenguaje español y que son refinados durante el entrenamiento completo. El presente artículo describe la implementación de Word2Vec como uno de los experimentos realizados durante el desarrollo del modelo de lenguaje MIA.
El algoritmo Word2Vec es un modelo de aprendizaje automático poco profundo no supervisado, lo que significa que no tuve la necesidad de etiquetar los datos de los que se alimenta (al menos de forma manual) a la red neuronal sobre la que esta basado, el único requisito es contar con un conjunto de datos lo suficientemente grande para poder obtener una buena calidad de embeddings, así que el primer paso es la obtención de los datos (una gran cantidad de ellos) para alimentar a Mia Embeddings y así poder entrenarlo.
Puedes encontrar una versión completa del código de este artículo en el repositorio oficial de experimentos con MIA, el modelo de lenguaje 100% mexicano.
Obtención y preparación de datos
Normalmente la primera fase de desarrollo (una vez analizado y comprendido el problema que se desea resolver) en cualquier proyecto relacionado con Machine Learning y/o Deep Learning es la obtención y preparación de los datos que se necesitarán para el entrenamiento, validación y prueba del mismo y es una de las fases en donde se requiere el mayor esfuerzo. En el caso del modelo MIA, el objetivo fue obtener una gran cantidad documentos de texto en lenguaje español lo cual representa un proyecto en si mismo debido a la escacez de estos (existen muchos datasets públicos disponibles, pero muy pocos especificamente en lenguaje español mexicano), para el caso particular de la implementación del modelo Word2Vec en este experimento con MIA utilizamos un dataset que consta de los archivos que encontrarás en el folder data de la estructura del proyecto que compartimos en el repositorio oficial de experimentos con MIA.
Analizando el modelo Word2Vec
La intuición detrás del modelo Word2Vec es que el significado de una palabra esta en función de su contexto (las N palabras que se encuentran antes y después de la palabra que se quiere predecir) y propuso dos posibles arquitecturas para su implementación.
CBOW: El objetivo de entrenamiento es predecir la palabra central en función del conjunto de palabras en su contexto.
Skipgram: El objetivo de entrenamiento es predecir el contexto en función de la palabra central.
Para el caso del modelo MIA decidí implementar la arquitectura CBOW. En ambas arquitecturas CBOW o Skipgram la red neuronal es poco profunda, esto es, consta unicamente de 2 capas, la capa de embeddings y una capa lineal totalmente conectada (ver Fig. 1), la única diferencia es en los datos de entrada a la red, que en el caso de CBOW y por ende MIA Embeddings son el contexto que consta de N palabras antes y después de la palabra actual a predecir y la salida es la predicción de la palabra central, así cada elemento de datos consta de una pareja ((p1, p2, p4, p5), p3) donde (p1, p2, p4, p5) representarian las variables independientes "x's" (el contexto) y (p3) la variable dependiente, "y's" o la gran verdad como normalmente se le conoce, mientras que en Skypgram es al contrario, la entreda es la palabra central y la predicción es el contexto.
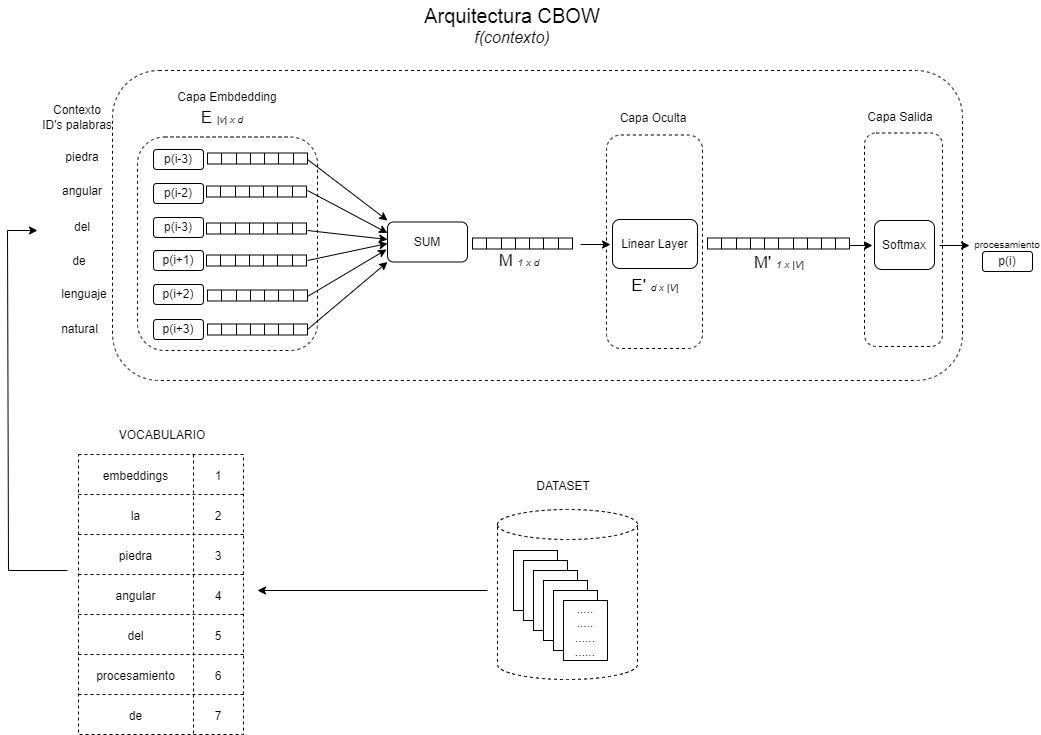
Fig. 1 - Diagrama alto nivel arquitectura CBOW
Implementando la arquitectura CBOW con Pytorch en MIA
Definiendo MiaEmbeddingsModel en código
En Pytorch, las arquitecturas basadas en redes nueronales como es el caso de la implementación CBOW en MIA Embeddings deben de extender de la clase base Module del paquete torch.nn, esta clase abstrae toda la lógica necesaria para la definición de las diferentes capas (la arquitectura del modelo) de las que constará la arquitectura que estamos definiendo, así como la lógica de computo del grafo resultante de la red neuronal (a través de la implementación específica del método forward que recibe un tensor como entrada), así que la clase MiaEmbeddingsModel extiende la clase Module de Pytorch y durante su inicialización creamos y configuramos 2 capas pre-definidas en Pytorch, la clase Embeddings y la clase Linear ambas importadas del paquete torch.nn, de esta forma, MiaEmbeddingsModel es un modelo de red neuronal poco profundo que solo tiene dos capas, una capa embeddgins y una capa lineal totalmente conectada como se describe en la arquitectura CBOW. El siguiente bloque de código es el responsable de la definición de la arquitectura en MiaEmbeddingsModel.
def __init__(self, vocabulary_size: int):
self.embeddings = nn.Embedding(
num_embeddings=vocabulary_size,
embedding_dim=MIA_EMBED_DIMENSION,
max_norm=MIA_EMBED_MAX_NORM,
)
self.linear = nn.Linear(
in_features=MIA_EMBED_DIMENSION,
out_features=vocabulary_size,
) Ahora bien, la clase Embeddings de Pytorch puede ser vista como un diccionario en donde la llave es la palabra y el valor una lista o arreglo con los embeddings calculados y que son iniciados aleatoriamente en un principio y que se actualizan durante el entrenamiento de acuerdo al algoritmo CBOW, además esta clase requiere de algunos parámetros adicionales, como son el tamaño del vocabulario (recordemos que el objetivo es calcular los embeddings de un conjunto de palabras únicas dentro de un conjunto de documentos de texto que representarán nuestro vocabulario) y la dimensionalidad de los embeddings que se desean calcular, word2vec sugiere un tamaño de 100 y 1000 pero en MIA lo establecí con un valor de 300 por cuestiones de experimentación, en el caso del tamaño del vocabulario este es calculado dinámicamente por medio del procesamiento de los documentos de texto que pudimos obtener y que utilizé como dataset. Otro aspecto importante es la implementación del método forward que ejecuta el paso de los datos de entrada a través de todas las capas de las que consta el módelo MiaEmbeddingsModel, y que de acuerdo a la arquitectura CBOW recibe como datos de entrada una lista de ids que representan los indices de las palabras dentro de nuestra capa embeddings, por tanto al pasar a través de esta primera capa obtendremos una matriz de N x MIA_EMBED_DIMENSION en donde N es la longitud de la lista de de ids recibida, posteriormente calculamos el promedio de cada columna y retornamos una matriz de una fila por MIA_EMBED_DIMENSION reduciendo de esta forma la dimensionalidad dejando listo todo para atravesar por la capa lineal y devolver el tensor cálculado como se muestra en el bloque de código siguiente.
def forward(self, input_word_ids):
x = self.embeddings(input_word_ids)
x = x.mean(axis=1)
x = self.linear(x)
return x Como se puede observar la implementación de la arquitectura del modelo no es tan "complicada" si aprovechamos las facilidades de los diferentes frameworks de deep learning como es el caso de Pytorch.
Procesamiendo de los datos y su carga
Bueno, ya tenemos nuestro modelo y ahora necesitamos entrenarlo alimentandolo con datos, muchos datos, sin embargo, los datos con los que contaba son un conjunto de documentos de texto mientras que el modelo MIA Embeddings requiere como entrada valores númericos (ids), ¿Como procesamos los datos para poder alimentar a nuestro modelo con valores númericos? y ¿Como cargamos los datos en batches para que el modelo los utilice para su entrenamiento?, afortunadamente Pytorch provee de facilidades para el procesamiento de diferentes tipos de datos y formatos, en particular, documentos de texto, de igual forma provee de clases útiles para la carga y procesamiento de datasets y son estas clases las que utilicé de forma personalizada para el procesamiento y la carga del dataset en el modelo MIA Embeddgins así como otras funciones de gran ayuda.
De acuerdo al diagrama de alto nivel de la arquitectura (ver Fig. 1) el algoritmo necesita de la construcción de un vocabulario el cual basicamente es un mapa donde la llave es una palabra y el valor asociado un número que representa el id de dicha palabra (normalmente el índice de la posición de la palabra dentro del vocabulario), dicho vocabulario proviene de nuestro conjunto de datos y puede consistir de todas las palabras únicas en dicho conjunto de datos o de aquellas palabras que se repiten más frecuentemente, para el modelo MIA, elegí la segunda opción. Entonces, para la construcción de dicho vocabulario necesité implementar lo siguiente:
Abrir el archivo.
Leer cada una de las lineas de texto.
Separar en tokens la linea de texto.
Calcular la frecuencia de cada palabra y determinar que palabra incluir de acuerdo a que tantas veces aparece en el documento.
Elegir aquellas palabras que se repiten más.
Asignar a cada palabra elegida un ID.
Retornar el vocabulario.
Para la implementación de la lógica anterior aproveche una libreria de Pytorch para el procesamiento de texto (pytorchtext) del cual tomé algunas funciones y clases, especificamente la función build_vocab_from_iterator y la clase Vocab definidas en el paquete torchtext.vocab, la función build_vocab_from_iterator require que le pasemos tres parámetros de entrada, un iterador sobre nuestra fuente de datos el cual leera cada linea de texto, una lista de simbolos especiales de nuestro vocabulario, y la frecuencia minima para incluir la palabra en el vocabulario que se desea crear, este último valor lo especifiqué a tráves de la constante MIA_VOCABULARY_MINWORD_FREQUENCY con un valor de 50 y la invocación al método build_vocab_from_iterator la realizamos a través de la siguiente función.
def buildVocabFromSpanishCorporaIterator(self, spanishCorporaIterator: any, tokenizer: any) -> Vocab:
vocab = build_vocab_from_iterator(
map(tokenizer, spanishCorporaIterator),
specials=["<unk>"],
min_freq=MIA_VOCABULARY_MINWORD_FREQUENCY,
)
vocab.set_default_index(vocab["<unk>"])
return vocabLa pieza faltante en el código anterior es la explicación del iterador de nuestros datos, el cuál implementé utilizando la libreria pytorchdata la cual gira en torno a la clase DataPipe y que también proporciona clases pre-construidas útiles para nuestro proposito de leer los archivos de texto y crear el vocabulario de acuerdo a este. Esta funcionalidad la codifiqué en la función MiaSpanishCorpora siguiente:
def MiaSpanishCorpora(root_data_dir: str, split_type: str):
if not is_module_available("torchdata"):
raise ModuleNotFoundError(
"Package 'torchdata' not found. Please install following instructions at 'https://github.com/pytorch/data'"
)
mia_corpora_dp = FileLister(root= os.path.join(root_data_dir, split_type), recursive=True).filter(lambda fname: fname.endswith('.txt'))
mia_corpora_dp = FileOpener(mia_corpora_dp, mode="b")
return mia_corpora_dp.readlines(strip_newline=False, decode=True, return_path=False) La función anterior recibe el directorio raíz en donde se ubican los datos a leer y el tipo de datos a considerar (datos para entrenamiento o datos para validación del modelo), esta función utiliza tres clases pre-definidas en la libreria pytorchdata y que facilitan la lectura de nuestra fuente de datos, FileLister (lista todos los archivos en el folder raíz especificados y devuelve una lista de los mismos incluido su ubicación), FileOpener (tomando como entrada la salida del FileLister abre cada uno de los archivos y retorna una lista de tuples con el nombre del archivo y su stream para lectura) y finalmente LineReader (el cual lee las líneas de texto de cada archivo abierto y retorna una lista de tuples con las líneas de texto para cada archivo).
Siguiendo el flujo de la arquitectura y sin olvidar que el objetivo es alimentar al modelo con datos númericos en lugar de texto vemos que una vez que hemos generado nuestro vocabulario este será invocado para la generación de los ids de entrada que necesita el modelo implementado en la clase MiaEmbeddingsModel, en otras palabras, los pasos durante el entrenamiendo son:
Leer la entrada (un parrafo de texto) a través de nuestro iterador de datos y un cargador de los mismos.
Generar los data points (x,y) con ayuda de nuestro cargador de datos y una función generadora de batches, collateFunction.
Entrenar al modelo con los batches generados.
De los pasos anteriores podemos darnos cuenta que requerimos de algunos funciones y objetos adicionales, un DataLoader y la función que genera los batches, la cual pasaremos como parámetro de la clase DataLoader de Pytorch. Dentro de esta función implementé la lógica necesaria para retornar una tupla que representa la muestra de datos esperada por el modelo MiaEmbeddingsModel, esto es, una lista con los ids del contexto (los valores de las x's) y otra lista con los ids de las palabras centrales que corresponden a cada contexto (los valores de las y's), la función de la que estoy hablando es conocida como collate_fn requerida cuando se necesita un comportamiento especial en el DataLoader para la generación de batches como en nuestro caso y que a continuación transcribo de nuestro código fuente:
def collateFunction(batch: any, text_pipeline: any) -> tuple:
batch_input, batch_output = [], []
for text in batch:
text_tokens_ids = text_pipeline(text)
if len(text_tokens_ids) < MIA_CONTEXT_LENGTH * 2 + 1:
continue
if MIA_MAXSEQUENCE_LENGTH:
text_tokens_ids = text_tokens_ids[:MIA_MAXSEQUENCE_LENGTH]
for idx in range(len(text_tokens_ids) - MIA_CONTEXT_LENGTH * 2):
token_id_sequence = text_tokens_ids[idx : (idx + MIA_CONTEXT_LENGTH * 2 + 1)]
output = token_id_sequence.pop(MIA_CONTEXT_LENGTH)
input_ = token_id_sequence
batch_input.append(input_)
batch_output.append(output)
batch_input = torch.tensor(batch_input, dtype=torch.long)
batch_output = torch.tensor(batch_output, dtype=torch.long)
return batch_input, batch_outputLo que ocurre dentro de la función generadora de batches anterior es lo siguiente:
La función recibe del DataLoader un batch, que es una lista de parafos de texto obtenidos de nuestra fuente de datos y a tráves de nuestro función iteradora.
Por cada parafo de texto en la lista se aplica una función que genera los ids de cada palabra en dicho parrafo (con ayuda del vocabulario realizando una búsqueda por llave y obteniendo el id correspondiente).
Por cada lista de ids se obtiene el contexto MIA_CONTEXT_LENGTH antes y despues así como el id de la palabra central y se van agregando a la listas batch_input y batch_output respectivamente.
Una vez procesada la lista de parrafos recibida se crean las matrices (tensores en pytorch) necesarias para el entrenamiento y se retornan como una tupla listas para ser consumidas por el modelo que estamos entrenando, MiaEmbeddingsModel.
La tupla retornada por la funcion collateFunction sera la que se pasará al modelo como datos de entrada para realizar los cálculos y finalmente obtener los valores optimizados de los embeddings.
Proceso de entrenamiento
El ciclo de entrenamiento de un modelo de deep learning es estándar y básicamente consiste en iterar sobre los datos un determinado número de épocas, y durante el entrenamiento de cada época se atraviesa todas las capas que conforman la arquitectura del modelo con el fin de obtener una salida del mismo (una predicción) que pasa por una funcion objetivo que se encarga de cálcular el error entre la gran verdad y la estimación obtenida y con base a esta información se actualizan los parámetros calculados con valores optimizados y se continua con el siguiente batch de datos hasta consumirlos todos y continuar con el entrenamiento de la siguiente época. Este ciclo de entrenamiento lo implementé en la función train de la clase MiaEmbeddingsTrainer incluido a continuación.
def executeTraining(self, model: MiaEmbeddingsModel, trainLoader: DataLoader, validLoader: DataLoader, lossFunction: any, optimizer: any, lrScheduler: any, trainDevice: any):
epochs = self.config["miaemb_epochs"]
t1d = time.time()
for epoch in range(epochs):
self._trainEpoch(model, trainLoader, lossFunction, optimizer, trainDevice)
self._validateEpoch(model, validLoader, lossFunction, trainDevice)
self.logger.info(
"Epoch: {}/{}, Train Loss={:.5f}, Val Loss={:.5f}".format(
epoch + 1,
epochs,
self.loss["train"][-1],
self.loss["val"][-1],
)
)
lrScheduler.step()
if self.config["miaemb_checkpoint_frequency"]:
self._saveCheckpoint(epoch, model)
t2d = time.time()
Conclusión
Es importante mencionar que el bloque encoder de la Arquitectura Transformer tiene precisamente la finalidad de calcular los embeddings de un vocabulario conformado por una cantidad astronómica de datos y que modelos como BERT, LLAMA o GPT entre muchos otros superan el algoritmo word2vec aprovechando el mecanismo de atención, pero también es inegable que word2vec fue y sigue siendo un parteaguas que dio paso a dichas arquitecturas ya que codifico el “significado” de las palabras en un espacio vectorial que agrupa "conceptos semánticos", de allá la idea de que la Arquitectura Transformer no inicia en blanco sino con una capa embeddings que se refina aún más durante el entreamiento a través de la paralelización (viendo los datos desde diferentes perspectivas) del mecanismo de atención. En el caso particular de MIA la idea de implementar word2vec fue experimentar con fuentes de datos en español y de preferencia español mexicano, evaluar la calidad de los embeddings calculados y medir su desempeño en tareas particulares donde simplemente se utilicen, también es importante mencionar que existen muchas implementaciones de las cuales podemos descargar los embeddigns y utilizarlos, sin embargo, recordemos que contar con un vocabulario del dominio del problema a abordar es importante por lo que si los embeddings que ocupamos fueron entrenados con textos en inglés o fuera del dominio de nuestra organización muy probablemente su desempeño sera menor. Además de todo lo anterior mi objetivo es acompañarte en tú viaje a la próxima frontera en IA y una estación obligada en ese camino es conocer a profundidad uno de los pilares sobre los que descansan muchos de los impresionantes modelos de lenguaje grandes actuales y que mejor forma que una implementación desde cero y a través de nuestro acompañante en dicha ruta, MIA, el modelo de lenguaje 100% mexicano.